A-Eye: Fahren mit den Augen der KI


Das Ziel dieser Arbeit ist die Anreicherung von Trainingsdaten für das autonome Fahren mit so genannten Corner Cases. Im Straßenverkehr sind Corner Cases kritische, seltene und ungewöhnliche Fahrsituationen, die eine Herausforderung für die Wahrnehmung durch KI-Algorithmen darstellen. Zu diesem Zweck hat sich die Arbeitsgruppe Stochastik von Prof. Hanno Gottschalk einen Prüfstand überlegt mit dem synthetische Corner Cases mit einem Human-in-the-Loop-Ansatz und der Open-Source-Fahrsimulationssoftware CARLA (https://carla.org/) erzeugt werden können. Für den Prüfstand wird ein semantisches Echtzeit-Segmentierungsnetz trainiert und so in die Fahrsimulationssoftware CARLA integriert, dass ein Mensch auf Basis der Vorhersage des Netzes fahren kann. Zusätzlich bekommt eine zweite Person die gleiche Szene aus der Original-CARLA-Ausgabe zu sehen und soll mit Hilfe einer zweiten Steuereinheit eingreifen (Tritt auf die Bremse oder Eingriff ins Lenkrad), sobald der semantische Fahrer ein gefährliches Fahrverhalten zeigt. Eingriffe deuten auf eine schlechte Erkennung einer kritischen Szene durch das Segmentierungsnetz hin und stellen dann einen Corner Case dar. In unseren Experimenten konnten wir zeigen, dass die gezielte Anreicherung von Corner Cases in den Trainingsdaten zu einer Verbesserung der Fußgängererkennung in sicherheitsrelevanten Situation im Straßenverkehr führt.
Preprint: https://arxiv.org/abs/2202.10803
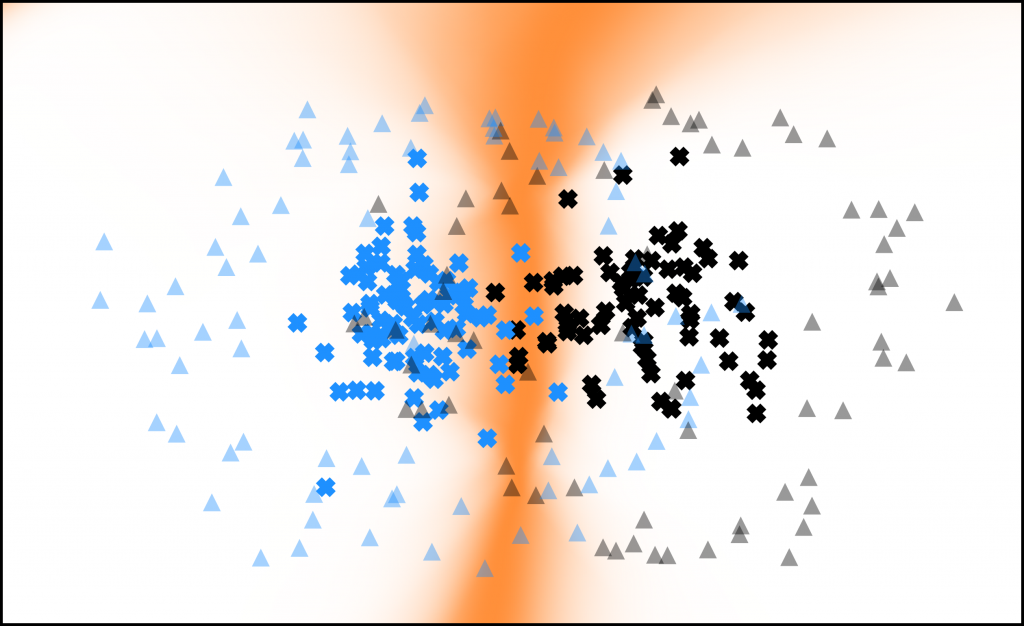
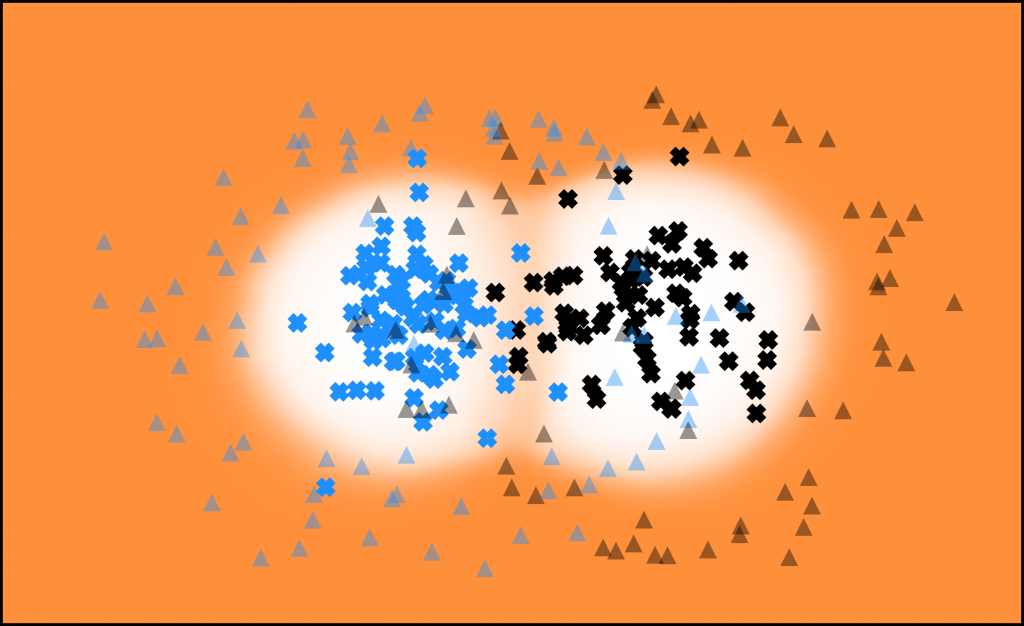



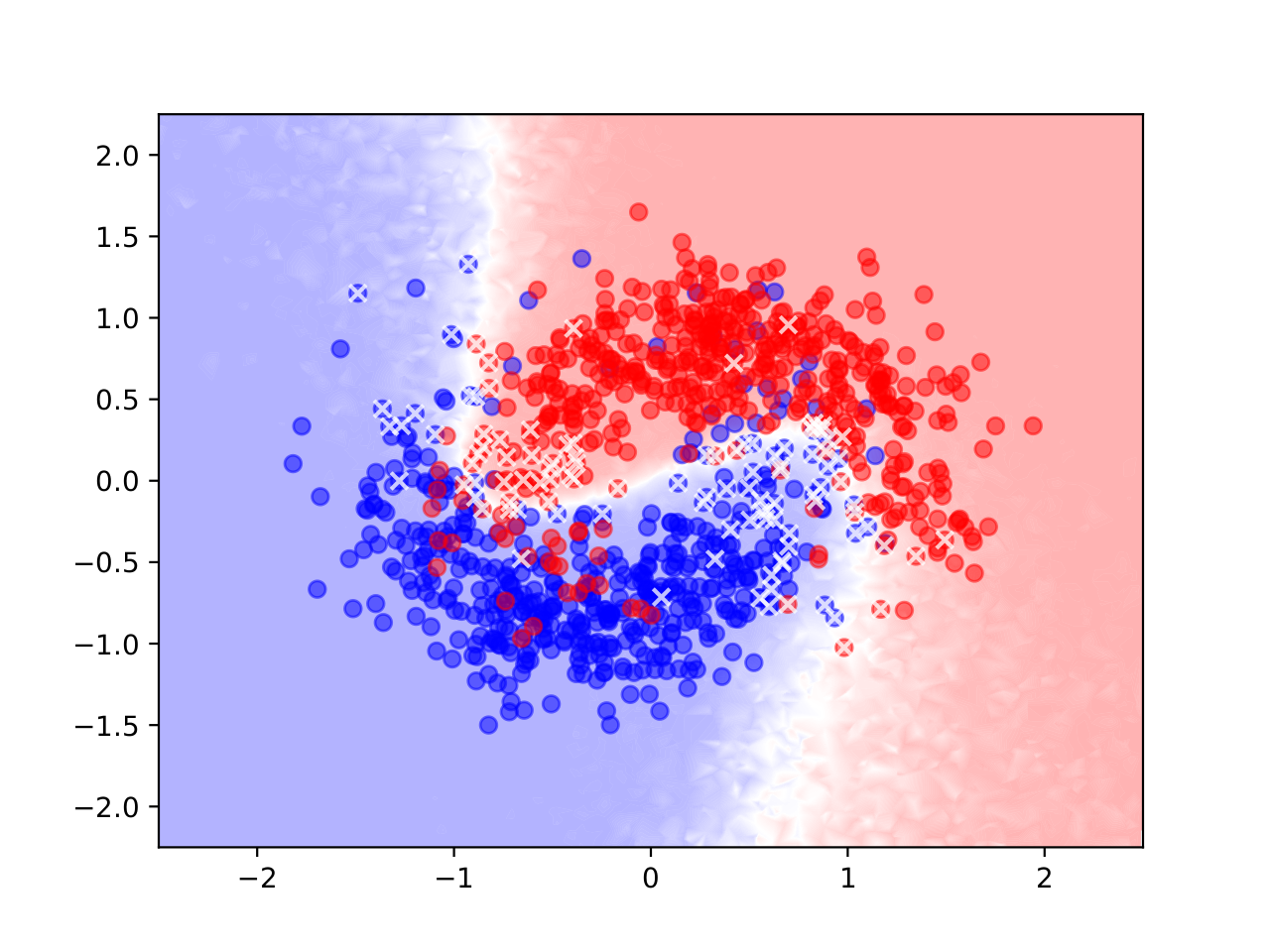
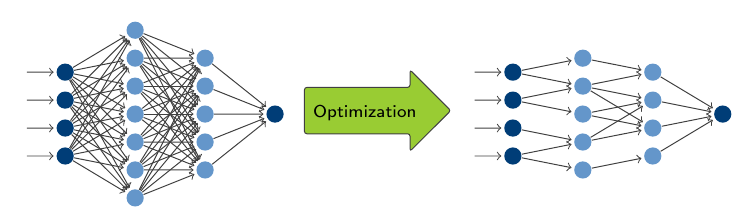 eim Design und Training tiefer neuraler Netzwerke sind Overparameterization (die Verwendung eines für die Aufgabe zu komplexen Netzwerkes) und Overfitting (das exakte Lernen der Trainingsdaten wodurch sich die Generalisierung auf andere Inputdaten verschlechtert) häufige auftretende Probleme. Oft werden Pruning- und Regularisierungstechniken verwendet um dem entgegen zu wirken. Diese Strategien bleiben jedoch meist dem Trainingsziel untergeordnet und führen unter Umständen zu zeit- und rechenintensiven Verfahren.
eim Design und Training tiefer neuraler Netzwerke sind Overparameterization (die Verwendung eines für die Aufgabe zu komplexen Netzwerkes) und Overfitting (das exakte Lernen der Trainingsdaten wodurch sich die Generalisierung auf andere Inputdaten verschlechtert) häufige auftretende Probleme. Oft werden Pruning- und Regularisierungstechniken verwendet um dem entgegen zu wirken. Diese Strategien bleiben jedoch meist dem Trainingsziel untergeordnet und führen unter Umständen zu zeit- und rechenintensiven Verfahren.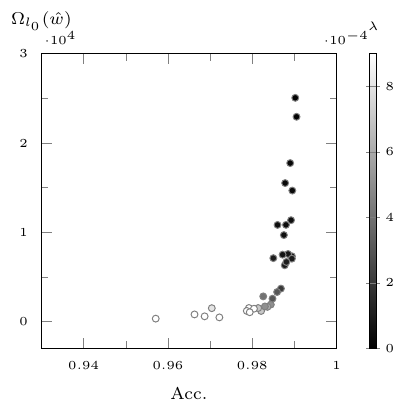

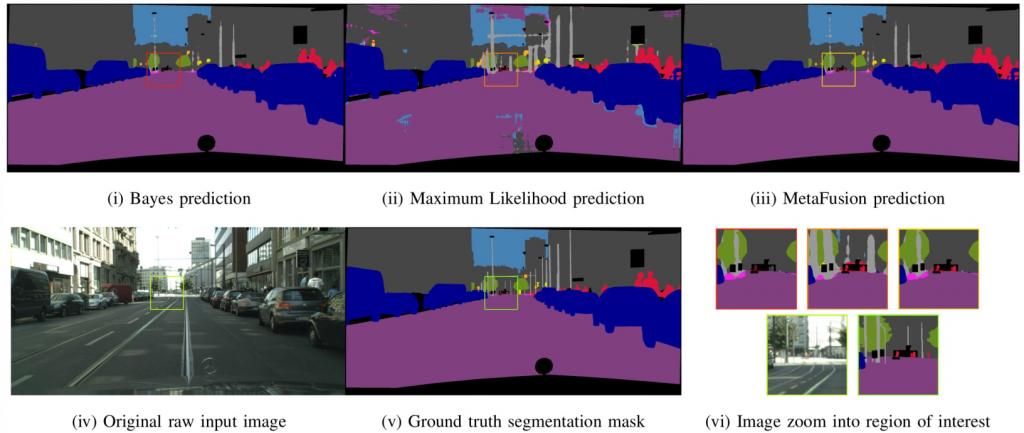
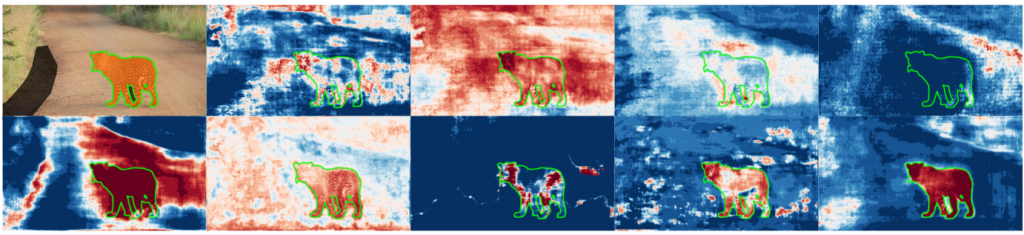
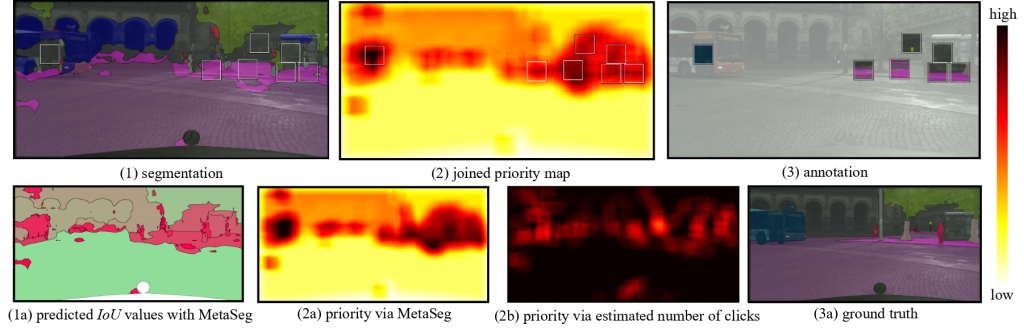
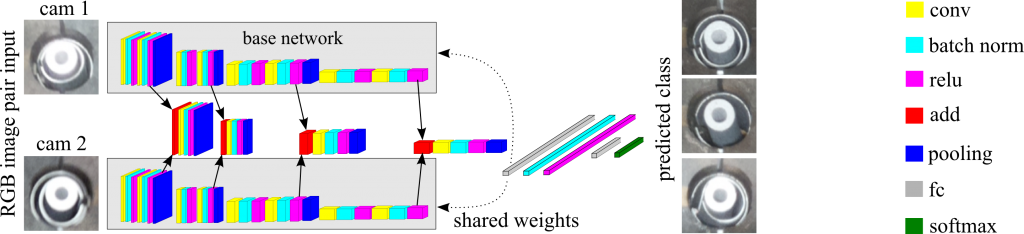
 In der semantischen Segmentierung von Straßenszenen mit neuronalen Netzen ist die Zuverlässigkeit von Vorhersagen von höchstem Interesse. Die Bewertung von neuronalen Netzen anhand von Unsicherheiten ist ein häufig verwendeter Ansatz, um Sicherheitsprobleme zu vermeiden. Da in Anwendungen wie dem automatisiertem Fahren, Sequenzen von Bildern zur Verfügung stehen, stellen wir einen zeitdynamischen Ansatz zur Untersuchung von Unsicherheiten und zur Beurteilung der Vorhersagequalität neuronaler Netze vor. Wir verfolgen Segmente über die Zeit und bilden Metriken pro Segment, sodass wir Zeitreihen von Metriken erhalten, mit denen wir die Vorhersagequalität beurteilen können. Dafür werden falsch positive Segmente sowie ein Performance Maß für die semantische Segmentierung vorhergesagt.
In der semantischen Segmentierung von Straßenszenen mit neuronalen Netzen ist die Zuverlässigkeit von Vorhersagen von höchstem Interesse. Die Bewertung von neuronalen Netzen anhand von Unsicherheiten ist ein häufig verwendeter Ansatz, um Sicherheitsprobleme zu vermeiden. Da in Anwendungen wie dem automatisiertem Fahren, Sequenzen von Bildern zur Verfügung stehen, stellen wir einen zeitdynamischen Ansatz zur Untersuchung von Unsicherheiten und zur Beurteilung der Vorhersagequalität neuronaler Netze vor. Wir verfolgen Segmente über die Zeit und bilden Metriken pro Segment, sodass wir Zeitreihen von Metriken erhalten, mit denen wir die Vorhersagequalität beurteilen können. Dafür werden falsch positive Segmente sowie ein Performance Maß für die semantische Segmentierung vorhergesagt.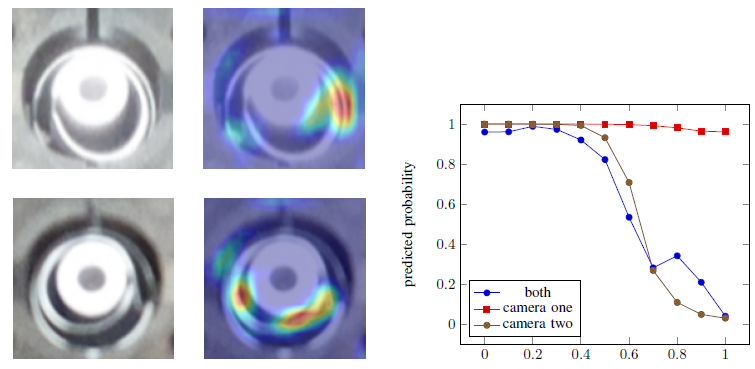
 Es gilt, die erreichte Position für die NRW.Druck- und Medienbranche zu behaupten und auszubauen! Die Digitalisierung hat unter dem Stichwort „Industrie 4.0“ bereits eine intensive Diskussion in der Branche ausgelöst.
Es gilt, die erreichte Position für die NRW.Druck- und Medienbranche zu behaupten und auszubauen! Die Digitalisierung hat unter dem Stichwort „Industrie 4.0“ bereits eine intensive Diskussion in der Branche ausgelöst.