 Deep Learning mit wenigen Labels
Deep Learning mit wenigen Labels
Im Deep Learning wird meist auf unstrukturierten Daten (z.B. Bildern oder Texten) eine Klassifikation oder Regression gelernt. Dabei kommen (tiefe) neuronale Netze zum Einsatz. Damit das Netz lernt, muss zu ausreichend vielen Daten eine sogenannte Ground Truth, d.h. das Wissen um die korrekte Klassifizierung, vorhanden sein. Die Erzeugung dieser Ground Truth, auch Labels genannt, kann kostspielig und zeitaufwändig werden. Dies ist eine Hürde, die es erschwert, Verfahren des Deep Learnings in der Praxis zum Einsatz zu bringen.
Das aktive Lernen und das halb-überwachte Lernen liefern zwei Ansätze, um mit wenigen Labels möglichst performante Netze anzulernen. Mehr...
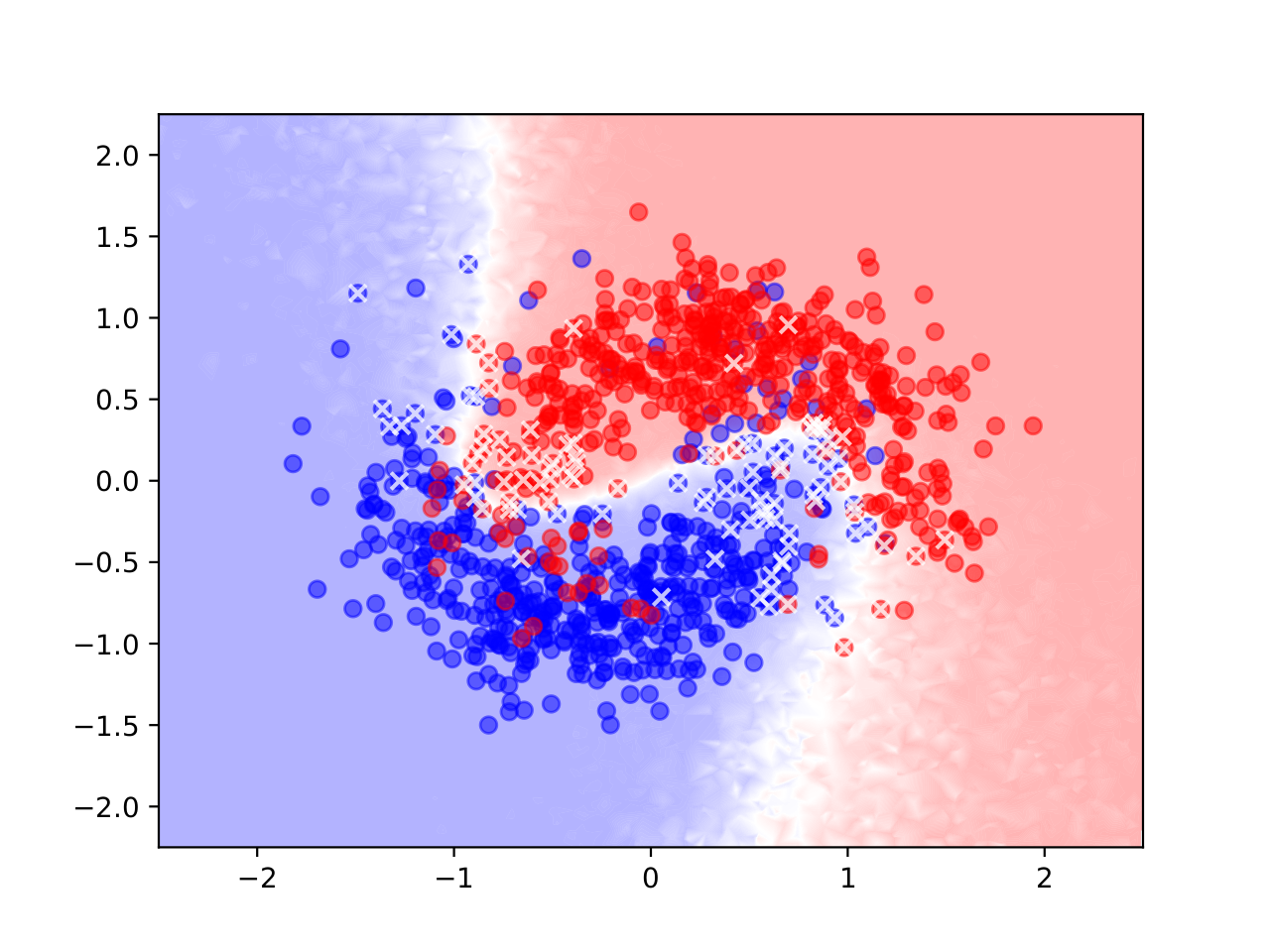
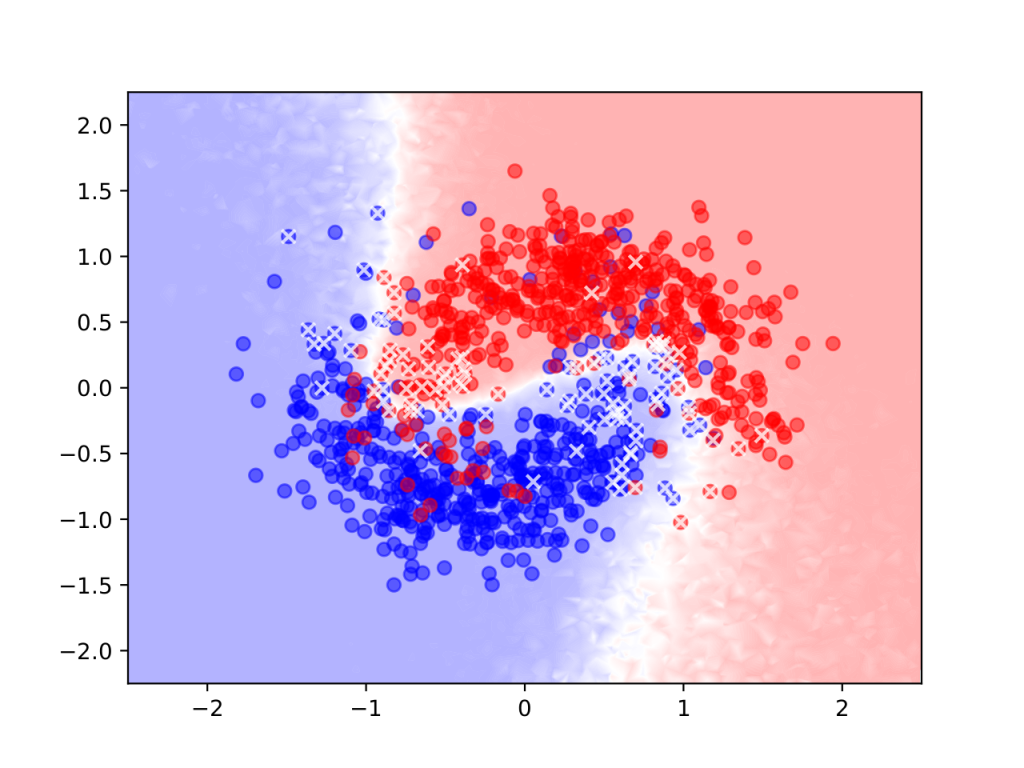
Mit diesen Ansätzen entwickeln Dr. Matthias Rottmann, Dr. Karsten Kahl und Professor Hanno Gottschalk Verfahren, durch die neuronale Netze in die Lage versetzen von wenigen Labels lernen. Im aktiven Lernen fragt das Neuronale Netz einen Experten oder Nutzer nach zusätzlichen Labels zu Daten, bei denen es sich besonders unsicher ist. Zur Bestimmung dieser Unsicherheit kommen Methoden der Bayeschen Inferenz zum Einsatz. Beim halb-überwachten Lernen werden ungelabelte Daten zum Training genutzt, d.h. das Neuronale Netz lernt auf diesen Daten durch Selbstbestätigung. Durch eine Kombination dieser Verfahren erreichen Matthias Rottmann, Karsten Kahl und Hanno Gottschalk auf standardisierten Benchmarks (Klassifikation von handschriftlichen Ziffern) sehr gute Resultate. Die Grafik zeigt ein Testproblem, bei dem das neuronale Netz die Punkte anhand ihrer Lage in der Ebene nach ihrer Farbe klassifizieren soll. Nur die durchkreuzten Punkten, d.h. zu 8% der abgebildeten Datenpunkte, wurden im Verlauf des Verfahrens gelabelt, der Farbverlauf im Hintergrund zeigt an, in welchem Bereich der Ebene welche Farbe vom neuronalen Netz vorhergesagt wird.

 Aufgabe des Gutachterausschusses für Grundstückswerte ist Schaffung von Markttransparenz auf dem Grundstücksmarkt sowie die Feststellung von Verkehrswerten von Immobilien.
Aufgabe des Gutachterausschusses für Grundstückswerte ist Schaffung von Markttransparenz auf dem Grundstücksmarkt sowie die Feststellung von Verkehrswerten von Immobilien. Deep Learning entwickelte sich aus der Neuroinformatik und Forschung zur künstlichen Intelligenz. Häufig wird die KI dabei als ‚Black Box‘ dargestellt, bei der man nicht verstehen kann, warum sie in der Lage ist bestimmte Probleme zu lösen. Mit unserer Vorlesung an der Bergischen Universität möchten wir die Teile der KI-Forschung identifizieren, die auf gesicherten mathematischen Grundlagen stehen – z.B. die Fähigkeit von großen Neuronalen Netzen, beliebige Funktionen zu approximieren, sowie das genaue Funktionieren von ‚Lernalgorithmen‘, das ‚No Free Lunch‘-Theorem oder den Zusammenhang zwischen Symmetrie und Convolutional Neural Networks. Zur Vorlesung gibt es praktische Übungen mit aktuellen Tools für Deep Learning (Keras/Tensorflow).
Deep Learning entwickelte sich aus der Neuroinformatik und Forschung zur künstlichen Intelligenz. Häufig wird die KI dabei als ‚Black Box‘ dargestellt, bei der man nicht verstehen kann, warum sie in der Lage ist bestimmte Probleme zu lösen. Mit unserer Vorlesung an der Bergischen Universität möchten wir die Teile der KI-Forschung identifizieren, die auf gesicherten mathematischen Grundlagen stehen – z.B. die Fähigkeit von großen Neuronalen Netzen, beliebige Funktionen zu approximieren, sowie das genaue Funktionieren von ‚Lernalgorithmen‘, das ‚No Free Lunch‘-Theorem oder den Zusammenhang zwischen Symmetrie und Convolutional Neural Networks. Zur Vorlesung gibt es praktische Übungen mit aktuellen Tools für Deep Learning (Keras/Tensorflow).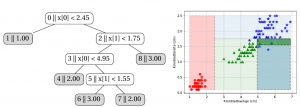
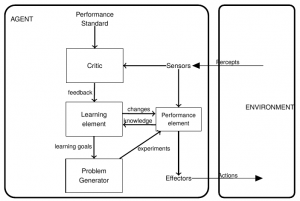 Im Wintersemester wird am Campus Velbert/Heiligenhaus (CVH) die Veranstaltung Angewandte KI im Rahmen des Master-Studiums angeboten. Dem Schwerpunkt bilden Deep Learning Verfahren und Reinforcement Learning in Zusammenhang mit Softwareagenten, als Nebenthema wird auch auf Bilderkennung mit Convolutional Neural Network (CNN) eingegangen. Praxisnahe Anwendungsfälle werden dabei in Zusammenarbeit mit den Kollegen von der Robotik, Fahrzeug- und Automatisierungstechnik vom CVH angeboten. Die Umsetzung erfolgt mittels Python und Keras. Seit 2018 steht auch ein Server mit Tesla-GPU-Unterstützung in der Veranstaltung zur Verfügung. Dozent ist Jörg Frochte. Voraussetzung für die Teilnahme sind Grundlegende Kenntnisse über klassische Verfahren des maschinellen Lernens.
Im Wintersemester wird am Campus Velbert/Heiligenhaus (CVH) die Veranstaltung Angewandte KI im Rahmen des Master-Studiums angeboten. Dem Schwerpunkt bilden Deep Learning Verfahren und Reinforcement Learning in Zusammenhang mit Softwareagenten, als Nebenthema wird auch auf Bilderkennung mit Convolutional Neural Network (CNN) eingegangen. Praxisnahe Anwendungsfälle werden dabei in Zusammenarbeit mit den Kollegen von der Robotik, Fahrzeug- und Automatisierungstechnik vom CVH angeboten. Die Umsetzung erfolgt mittels Python und Keras. Seit 2018 steht auch ein Server mit Tesla-GPU-Unterstützung in der Veranstaltung zur Verfügung. Dozent ist Jörg Frochte. Voraussetzung für die Teilnahme sind Grundlegende Kenntnisse über klassische Verfahren des maschinellen Lernens. Es gilt, die erreichte Position für die NRW.Druck- und Medienbranche zu behaupten und auszubauen! Die Digitalisierung hat unter dem Stichwort „Industrie 4.0“ bereits eine intensive Diskussion in der Branche ausgelöst.
Es gilt, die erreichte Position für die NRW.Druck- und Medienbranche zu behaupten und auszubauen! Die Digitalisierung hat unter dem Stichwort „Industrie 4.0“ bereits eine intensive Diskussion in der Branche ausgelöst.