Netzwerkoptimierung mit einem multikriteriellen Lernansatz
B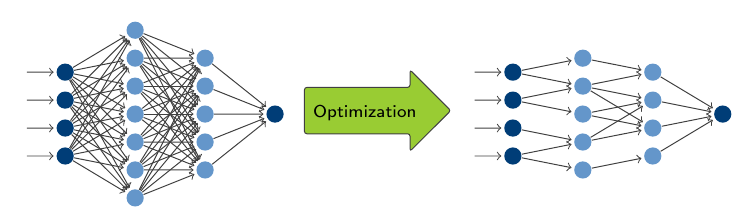 eim Design und Training tiefer neuraler Netzwerke sind Overparameterization (die Verwendung eines für die Aufgabe zu komplexen Netzwerkes) und Overfitting (das exakte Lernen der Trainingsdaten wodurch sich die Generalisierung auf andere Inputdaten verschlechtert) häufige auftretende Probleme. Oft werden Pruning- und Regularisierungstechniken verwendet um dem entgegen zu wirken. Diese Strategien bleiben jedoch meist dem Trainingsziel untergeordnet und führen unter Umständen zu zeit- und rechenintensiven Verfahren.
eim Design und Training tiefer neuraler Netzwerke sind Overparameterization (die Verwendung eines für die Aufgabe zu komplexen Netzwerkes) und Overfitting (das exakte Lernen der Trainingsdaten wodurch sich die Generalisierung auf andere Inputdaten verschlechtert) häufige auftretende Probleme. Oft werden Pruning- und Regularisierungstechniken verwendet um dem entgegen zu wirken. Diese Strategien bleiben jedoch meist dem Trainingsziel untergeordnet und führen unter Umständen zu zeit- und rechenintensiven Verfahren.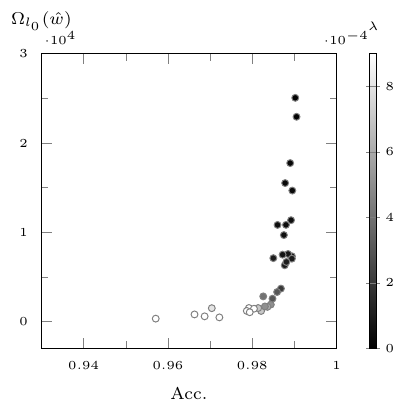
Wir schlagen eine multikriterielle Perspektive auf das Training neuronaler Netze vor, indem die Vorhersagegenauigkeit und die Netzwerkkomplexität als zwei konkurrierende Zielfunktionen in einem bikriterielle Optimierungsproblem betrachtet werden.
Unsere Ansätze testen wir auf CNNs (convolutionary neural networks) zur Bildklassifikation mit Crossentropy als Maß für die Vorhersagegenauigkeit, während wir die l1-Penaltyfunktion verwenden, um die Komplexität des Netzwerks zu bewerten. Letztere wird mit einem sogenannten Intratraining-Pruning kombiniert, das die Komplexitätsreduktion verstärkt und nur marginale zusätzliche Rechenkosten erfordert.
Wir vergleichen zwei verschiedene Optimierungsparadigmen: Zum einen verwenden wir einen Skalarisierungsansatz, der das bikriterielle Problem in eine Reihe von Skalarisierungen transformiert. Auf der anderen Seite implementieren wir ein stochastisches Gradientenabstiegsverfahren, das eine Pareto-optimale Lösung generiert, ohne dabei Präferenzinformationen zu benötigen.
Numerische Ergebnisse an CNNs bestätigen, dass eine signifikante Komplexitätsreduktion neuronaler Netze mit vernachlässigbarem Genauigkeitsverlust möglich ist.